
Bio
I am a PhD at CMU’s Robotics Institute, specializing in dexterous manipulation at the intersection of robot learning and model-based planning. My main line of work is generating high-quality plans for dexterous manipulation and using them as synthetic demonstrations to accelerate RL training. I’m passionate about continuing to bring my strong classical robotics background (planning, controls, optimization) to improving the efficiency and robustness of RL.
Previously, I worked on learned safe control for quadrotors and multi-task RL for locomotion. I care deeply about making algorithms work on real hardware, and I’ve shipped all my research on physical systems: bimanual KUKA, quadrotors, and legged millirobots.
At CMU, I am advised by Changliu Liu and John Dolan, and a recipient of the Qualcomm Graduate Fellowship. I also spent a few semesters on the Dexterous Mobile Manipulation team at Robotics and AI Institute. Prior to CMU, I did my undergrad in EECS at UC Berkeley, where I worked with Sergey Levine on deep RL for robotics.
You can reach me at simin.liu.1314 -at- gmail dot com
I am on the job market — please reach out if you have a relevant role.
News
- [March 2026] Talk at Duke Manipulation Seminar on contact-rich manipulation
- [March 2026] Talk at CMU Manipulation Seminar on contact-rich manipulation
- [Jan 2025] Paper submitted to IEEE T-RO.
- [April 2025] Paper accepted at ACM Transactions on Cyber-Physical Systems
- [Sept 2024] Started research internship at the Robotics and AI Institute, with Tao Pang
- [Jun 2024] Paper accepted at ECC
- [May 2023] Selected for Qualcomm Graduate Fellowship
- [April 2023] Paper accepted at ICLR
- [Sept 2022] Paper accepted at CORL
Selected Projects
Dexterous, Contact-Rich Manipulation
Building learning and planning algorithms for dexterous, contact-rich manipulation, where the full arm is used to move objects, not just the end-effector. Contact-rich manipulation is more challenging and more expressive than pick-and-place.
Higher-Quality Model-Based Planning
We built a planner that enables a bimanual system to move large, heavy objects using whole-arm contact. Unlike prior sampling-based approaches, which could produce whole-arm plans but at poor quality, this planner globally optimizes over grasp sequencing and in-grasp motion jointly. This joint optimization produces consistent, efficient plans suitable for hardware deployment and reinforcement learning.
Our method generates short, direct plans that leverage all manipulator surfaces, not just end-effectors.
Learning from Planner-Generated Demonstrations
(Ongoing work): Synthetic data avoids the cross-embodiment transfer issues of human data, and is therefore a promising additional data source for today's VLAs and RL algorithms. Teleoperation is also often awkward for contact-rich manipulation. Building on our planner for contact-rich manipulation, we're using its outputs as synthetic demonstrations for RL, and measuring how much they accelerate training and where the gains are largest.








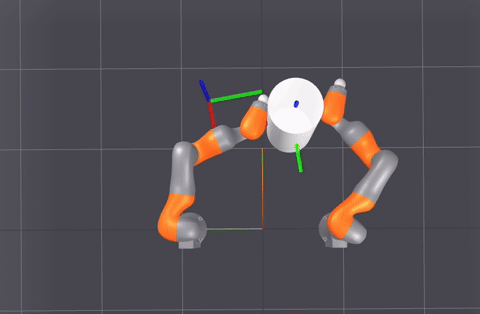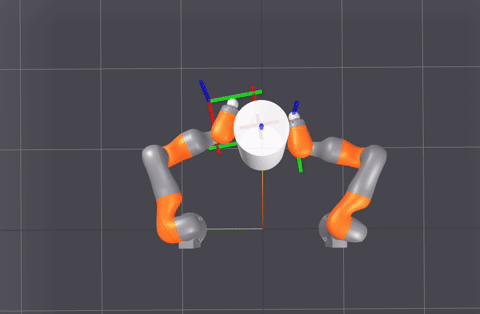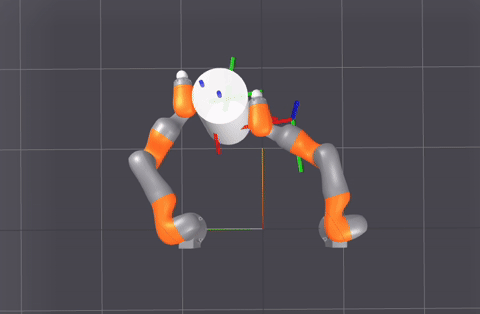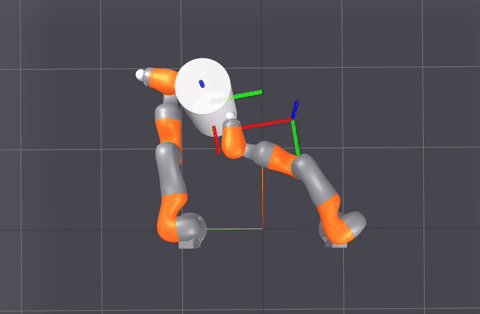
A sampling of planner-generated demonstrations for different (start, goal) queries.
Safe Control
Built full-stack safe control systems for agile quadrotors, where a safety filter wraps a nominal planner or controller and intervenes only when needed.
Safe Control for Uncertain Systems
Most safety filter synthesis approaches assume a known model, which is impractical. We synthesized robust-adaptive safety filters for nonlinear systems with unknown model parameters. The filter can be combined with online parameter estimation for end-to-end safety. Generated a collision-avoidance filter for a quadrotor with unknown drag in minutes on a regular laptop CPU.
Our safety filter keeps the drone inside the geofence despite unknown wind gusts.
Safe Control for High-Dimensional Systems
Grid-based RL can synthesize safety filters via an optimal control formulation, but it quickly becomes intractable beyond ~6D. We take inspiration from Q-learning and nonlinear control and introduce "neural control barrier functions", a neural safety filter parameterization that scales synthesis to systems with high state dimension. We learn a pendulum-balancing filter for a 10D quadrotor-pendulum in under 2 hours, and it intervenes orders of magnitude less often than an MPC-based safety filter.
Our safety filter prevents the pendulum from falling while the nominal controller stabilizes the quadrotor (10D quadrotor–pendulum system).
Multitask RL for Adaptive Locomotion
Model-based methods and standard RL both struggle to generalize locomotion controllers to previously unseen disturbances. We develop a multitask model-based RL algorithm that trains an adaptable dynamics model on a few hours of domain-randomized data — scenarios like leg loss, terrain variation, and payload changes. We demonstrate a 3–8x increase in path-following reward over a no-adaptation baseline on unseen disturbances.
The robot closely tracks the path despite leg loss, terrain changes, payload variation, and state-estimation error.